Tiny Transformer for Next-Token Prediction
Overview
Implemented transformer model for next-token prediction on 581K Shakespeare tokens, systematically analyzing 7 variants to understand how hyperparameters affect performance.
Key Results
- 3.69 perplexity with vocabulary size=260 (51% improvement over baseline)
- Baseline: 7.53 perplexity with vocab=500
- Learning rate optimization (0.01 vs 0.001) provided 27% improvement at no extra cost
- Batch size trade-off: Smaller batches (128) performed well but took 2.3× longer
Architecture
- 2 transformer blocks with single-head self-attention
- RMSNorm, causal masking, residual connections
- 493,940 total parameters
- Trained on Tesla T4 GPU (~13 min/model)
Systematic Hyperparameter Analysis
| Variant | Key Change | Perplexity | Insight |
|---|---|---|---|
| v1 (baseline) | - | 7.527 | Strong baseline, minimal overfitting |
| v2 | LR: 0.01 | 5.460 | Higher LR finds better solution |
| v3 | Batch: 128 | 5.366 | Better but 2.3× slower |
| v5 | Vocab: 260 | 3.690 | Best: optimal vocab for dataset |
| v4 | Seq: 25 | 8.339 | Shorter context hurts |
| v6 | FFN: 256 | 9.278 | Reduced capacity degrades |
| v7 | Embed: 64 | 10.851 | Insufficient embedding space |
Technical Stack
Python • PyTorch • Hugging Face Tokenizers • Google Colab
What I Learned
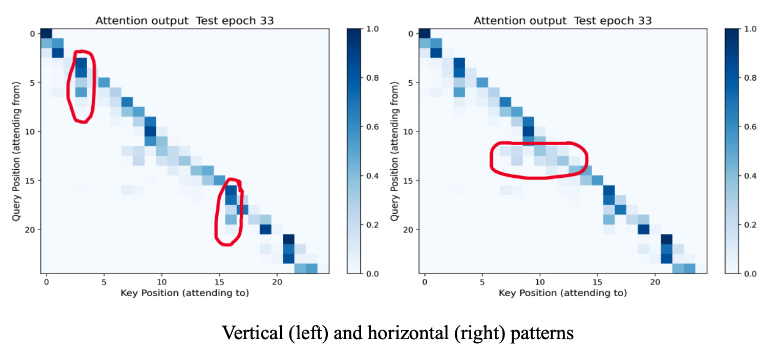
The biggest surprise was vocabulary size—reducing from 500 to 260 gave 51% perplexity improvement because smaller vocab meant each token appeared more frequently, allowing the model to learn robust embeddings rather than spreading capacity across rare tokens. This taught me that matching model capacity to dataset characteristics matters more than simply maximizing parameters. The attention visualization revealed hierarchical patterns where certain tokens act as information hubs, providing insight into what transformers actually learn.